Привет, чарт!
ДЕНЬ 01

Как перестать бояться нового и начать делать хорошие визуализации
Сегодня мы научимся строить основные виды графиков и диаграмм, наиболее востребованные для работы. Познакомимся с процессом работы с визуализацией в Yandex DataLens и разберем анатомию чартов. Соберем компоненты визуализации и подходы к построению. На примере наиболее популярных и востребованных видов визуализации потестируем основные параметры настроек DataLens.
Наша первая практика пройдет на датасете по вашим телефонным звонкам, которые вы сможете выгрузить и подготовить для анализа самостоятельно. Посмотрим, на какие вопросы можно будет найти визуальные ответы. Стартуем с общей схемы перцептивного восприятия и базовых принципов психологии визуализации. Полетели в DataLens.
Теория дня
Как мы видим данные вокруг нас, какие виды визуализации доступны и как выбрать правильный вид диаграммы


Как работают визуализации
От данных из реальной жизни к диаграммам
Давайте посмотрим на то, как собираемые в огромном количестве данные из нашей каждодневной жизни начинают иметь ценность.
Возьмем очень наглядный и простой пример – данные с вашего мобильного телефона. Каждый день мы пользуемся смартфонами и планшетами с сим-картами, совершая звонки, отправляя и получая смс (все еще!) и используя мобильный интернет.
Данные с наших мобильных телефонов собираются в огромном количестве. Только представьте! Кто, кому, когда, из какой точки на карте, в какую точку на карте, продолжительность разговора и объем переданных мегабайтов, скорее всего и те сайты, которые вы посещали, и страницы, которые загружали, и много чего еще.
Возьмем очень наглядный и простой пример – данные с вашего мобильного телефона. Каждый день мы пользуемся смартфонами и планшетами с сим-картами, совершая звонки, отправляя и получая смс (все еще!) и используя мобильный интернет.
Данные с наших мобильных телефонов собираются в огромном количестве. Только представьте! Кто, кому, когда, из какой точки на карте, в какую точку на карте, продолжительность разговора и объем переданных мегабайтов, скорее всего и те сайты, которые вы посещали, и страницы, которые загружали, и много чего еще.

Но что мы можем сделать с такими данными? Можем ли мы попытаться создать из них ценность для себя и найти ответы на те вопросы, которые нам важны? Какой путь они проходят?
Сначала данные собираются в «сыром» виде, в совсем неудобном для восприятия человеком формате. Это огромные массивы данных с большим количеством метрик и параметров.
Затем данные преобразовываются в более агрегированный датасет, в котором мы можем выделить категории и показатели и их агрегации
И конечно, нам надо задать вопросы к нашим данным, чтобы мы знали какие ответы искать. Ведь данные сами по себе не имеют никакого смысла. Они должны помогать нам в оценке обстановки, принятии решений, разрешении проблем или постановке целей.

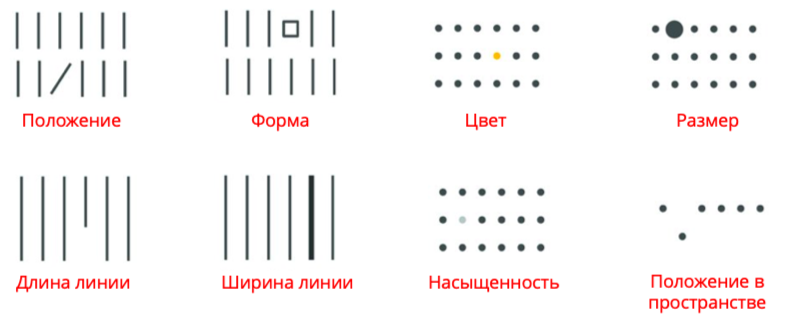

Мы не случайно можем легко считывать визуализации — все диаграммы основываются на специальных визуальных атрибутах (preattentive attributes). Они посылают нам сигналы, которые мы считываем нашими органами зрения и осознаем подсознательно.
Да, звучит немного волшебно, но так и есть! Например, мы интуитивно понимаем, что одно число больше другого, потому что один столбец выше, чем другие. А это всего лишь атрибут длины линии!

При этом разные визуальные атрибуты передают информацию с разной точностью. То есть одни визуализации доносят данные более точно, чем другие. Это не значит, что одни диаграммы хуже, чем другие, просто они используются для разных целей. В одних (точечных, линейных) важны детали, а в других – паттерны, тренды, тенденции.

Поставив нужные вопросы и представив данные визуально, мы переходим во вторую часть путешествия данных: там, где кто-то уже будет пытаться прочитать наши данные и понять их смысл. Неважно кто это будет — вы, как автор диаграммы, или кто-то еще, для кого вы ее делали. Путь восприятия визуальных данных у всех одинаков.

Свет, попадая в наши глаза, стимулирует сетчатку, которая посылает импульсы в очень краткосрочную память, в которой считываются визуальные атрибуты, и создается первичный образ того, что мы видим. Мозг выступает в роли очень быстрого процессора и обрабатывает полученный образ моментально и подсознательно.
Центр Нейронных исследований Нью Йорка изучил процесс того, как мы видим зрительной корой мозга. Сначала информация поступает в первичную зрительную кору, где происходит анализ ориентации отдельных линий объекта (на примере выше — область мозга внизу справа). Потом идет разделение на два потока: на «где» и на «что». В «где» строится карта местности, а в «что» — сборка образов, добавление цвета и контрастности, и в самом конце — распознавание сложных образов и их категоризация.
Центр Нейронных исследований Нью Йорка изучил процесс того, как мы видим зрительной корой мозга. Сначала информация поступает в первичную зрительную кору, где происходит анализ ориентации отдельных линий объекта (на примере выше — область мозга внизу справа). Потом идет разделение на два потока: на «где» и на «что». В «где» строится карта местности, а в «что» — сборка образов, добавление цвета и контрастности, и в самом конце — распознавание сложных образов и их категоризация.

Более того, в визуализации данных с успехом применяются принципы гештальта — набора естественных законов, по которым люди целостно воспринимают разрозненные объекты. В начале прошлого века ряд ученых изучали, как люди считывают значимые смыслы из хаоса вокруг них. Они выявили набор естественных законов человеческого восприятия, по которым люди группируют схожие объекты в единое целое.
С помощью результатов этих исследований, мы можем понимать как человек группирует похожие элементы, распознает шаблоны, упрощает сложные изображения. «Гештальт» — это термин, который был выбран для обозначения единицы такого целостного опыта. В визуальном дизайне он помогает сделать информационные продукты интуитивно понятными для пользователя.
С помощью результатов этих исследований, мы можем понимать как человек группирует похожие элементы, распознает шаблоны, упрощает сложные изображения. «Гештальт» — это термин, который был выбран для обозначения единицы такого целостного опыта. В визуальном дизайне он помогает сделать информационные продукты интуитивно понятными для пользователя.
Подробнее про Гештальт принципы...
Вот краткое описание принципов Гештальт
Принцип подобия — Мы воспринимаем похожие по одному признаку элементы как единое целое, даже если по другим признакам эти элементы отличаются. Основные объединяющие признаками — форма, цвет, размер.
Принцип близости — Мы воспринимаем элементы, которые расположены близко друг к другу, как связанные, и отличаем их от элементов, которые отделены друг от друга.
Принцип замкнутости — Мозг группирует элементы как схожие, если они находятся в одной и той же закрытой области.
Принцип непрерывности — Мозг группирует элементы как схожие, определяя взаимосвязи по линиям, кривым или последовательности форм. Помните, что человеческий глаз привык отмечать пути и следовать по ним.
Принцип смыкания — Мы предпочитаем законченные формы, поэтому мозг автоматически заполняет промежутки между элементами, чтобы воспринимать неполные объекты как целое изображение.
Принцип подобия — Мы воспринимаем похожие по одному признаку элементы как единое целое, даже если по другим признакам эти элементы отличаются. Основные объединяющие признаками — форма, цвет, размер.
Принцип близости — Мы воспринимаем элементы, которые расположены близко друг к другу, как связанные, и отличаем их от элементов, которые отделены друг от друга.
Принцип замкнутости — Мозг группирует элементы как схожие, если они находятся в одной и той же закрытой области.
Принцип непрерывности — Мозг группирует элементы как схожие, определяя взаимосвязи по линиям, кривым или последовательности форм. Помните, что человеческий глаз привык отмечать пути и следовать по ним.
Принцип смыкания — Мы предпочитаем законченные формы, поэтому мозг автоматически заполняет промежутки между элементами, чтобы воспринимать неполные объекты как целое изображение.
Работа с данными – сложный многоуровневый процесс, состоящий из нескольких этапов

Как работают чарты в DataLens
Теперь перейдем от теории к более практическому...
Визуализация в DataLens — это чарт. Чарты создаются в визарде на основе данных из датасета — чуть дальше посмотрим как это работает. На базе одного датасета может быть создано неограниченное количество чартов, которые могут быть добавлены в дашборды.
Визард — это окно, в котором создают и редактируются чарты #.
Рабочая область в интерфейсе визарда разделена на три основные панели:
Визард — это окно, в котором создают и редактируются чарты #.
Рабочая область в интерфейсе визарда разделена на три основные панели:
- Панель датасета, где отображаются доступные поля: Измерения и Показатели. Вы можете добавить в список вычисляемое поле.
- Панель настройки визуализации, где можно выбрать тип чарта. Для каждого типа доступен свой набор секций (например, ось X, ось Y, фильтры и т. д.), куда можно перетаскивать поля. Как раз эту область и рассмотрим далее подробнее.
- Панель превью, где отображается визуализация.

Давайте посмотрим на пару примеров чартов.
Пример сделан на основе датасета по сервису Kickstarter — краудфандинговой площадки по сбору средств на реализацию идей проектов. На площадке можно опубликовать свою идею для любого проекта — от съемки фильма и создания компьютерной игры до проведения выставки на Марсе и разработки дрона-доставщика пиццы. Благодаря такому разнообразию, на сервисе много категорий и подкатегорий проектов. Также, есть люди, которые жертвуют деньги, чтобы проект смог достичь финансовой цели.
Пример 1. Линейчатая диаграмма, в которой показано в каких основных категориях было больше всего бэкеров — людей, поддержавших проекты (поле Пожертвовало как раз содержит в себе количество этих людей).
Посмотрите на панель левее графика:
Пример сделан на основе датасета по сервису Kickstarter — краудфандинговой площадки по сбору средств на реализацию идей проектов. На площадке можно опубликовать свою идею для любого проекта — от съемки фильма и создания компьютерной игры до проведения выставки на Марсе и разработки дрона-доставщика пиццы. Благодаря такому разнообразию, на сервисе много категорий и подкатегорий проектов. Также, есть люди, которые жертвуют деньги, чтобы проект смог достичь финансовой цели.
Пример 1. Линейчатая диаграмма, в которой показано в каких основных категориях было больше всего бэкеров — людей, поддержавших проекты (поле Пожертвовало как раз содержит в себе количество этих людей).
Посмотрите на панель левее графика:
- в область Y добавлено поле Основная категория — оно формирует ось Y и создает подписи к визуализациям. Мы видим перечисление Games, Design, Technology… это все значения из поля Основная категория
- в область Х добавлено поле sum(Пожертвовало) — оно формирует ось Х и добавляет количественное выражение к нашим категориям. При этом, поле проагрегировано функцией суммирования (sum) — мы поставили такую настройку на последнем этапе загрузки датасета.

На цвет визуализации сейчас ничего не влияет, а вот на сортировку — да! Туда тоже добавлено поле sum(Пожертвовало) — т. е. категории идут в убывающем порядке по величине этого поля (для порядка по убыванию или возрастанию есть специальный значок).
В подписи визуализации добавлен тот же показатель, что и на оси — сумма людей, которые пожертвовали деньги.
И последнее в этом списке — фильтры. Фильтры помогают нам ограничивать данные, которые в итоге показываются на чарте, причем с помощью разных операций логики (начинается на abc…, содержит abc…, равно abc…). Мы оставим на чарте только те проекты, Статус которых — successful, т. е. эти проекты оказались успешными и смогли выполнить цель по сбору денег.
В подписи визуализации добавлен тот же показатель, что и на оси — сумма людей, которые пожертвовали деньги.
И последнее в этом списке — фильтры. Фильтры помогают нам ограничивать данные, которые в итоге показываются на чарте, причем с помощью разных операций логики (начинается на abc…, содержит abc…, равно abc…). Мы оставим на чарте только те проекты, Статус которых — successful, т. е. эти проекты оказались успешными и смогли выполнить цель по сбору денег.

Просто перетаскивайте поля из панели данных слева на нужные вам секции визуализаций в визарде – визуализация будет автоматически обновляться
Посмотрим на другой пример уже на основе нового набора данных.
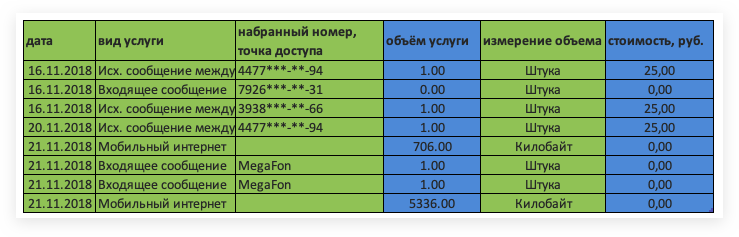
Эти данные показывают детализацию звонков от мобильного оператора Мегафон – выгрузка данных показывает операции по звонкам, смс и использованию мобильного интернета за 4 месяца. В данных есть вид операции, тарифицируемый объем услуг и их стоимость. Этот датасет вы сможете скачать в блоке ПРАКТИКА и повторить разбираемые графики.
Пример 2. Посмотрим на динамику изменения "тарифицируемого объема" мобильного интернета в разбивке по месту, в котором мы им пользовались.
Эти данные показывают детализацию звонков от мобильного оператора Мегафон – выгрузка данных показывает операции по звонкам, смс и использованию мобильного интернета за 4 месяца. В данных есть вид операции, тарифицируемый объем услуг и их стоимость. Этот датасет вы сможете скачать в блоке ПРАКТИКА и повторить разбираемые графики.
Пример 2. Посмотрим на динамику изменения "тарифицируемого объема" мобильного интернета в разбивке по месту, в котором мы им пользовались.
Важно! В DataLens существуют лимиты на отображение данных на визуализациях. На большинстве чартов стоит ограничение на 75 000 строк, которое чарт может отобразить. Если вы не видите свою визуализацию и видите ошибку лимита – примените ограничивающий фильтр.
Подробнее про лимиты чартов здесь.
Подробнее про лимиты чартов здесь.
При показе данных во времени, то есть в тех чартах, где мы используем поле Даты, мы можем изменять тип визуальной группировки дат: выбирать показ с округлением по годам, месяцам, неделям или дням. Если у вас в данных есть время, то вы также можете округлять данные к часам и минутам.
Эти настройки доступны по клику на иконку календаря в секции визарда.
Эти настройки доступны по клику на иконку календаря в секции визарда.


В нижней части графика располагается цветовая легенда, цвета которой можно поменять на шестеренке в области Цвета.
На самом деле, в окне визарда достаточно большое количество дополнительных настроек, которыми вы можете пользоваться. Кликайте на подсвечиваемые места в окошках интерфейса.
Например, в настройках осей X и Y, а также в настройках Цвета — кликните на шестеренку в верхнем правом углу, чтобы открыть настройки отображения.
На самом деле, в окне визарда достаточно большое количество дополнительных настроек, которыми вы можете пользоваться. Кликайте на подсвечиваемые места в окошках интерфейса.
Например, в настройках осей X и Y, а также в настройках Цвета — кликните на шестеренку в верхнем правом углу, чтобы открыть настройки отображения.

Не забудьте сохранить созданный чарт – для этого есть специальная большая желтая кнопка в верхнем правом углу. При сохранении вы можете выбрать нужное расположение чарта и задать название.
А для того, чтобы перейти к другим чартам или другим объектам внутри DataLens (подключениям, датасетам или дашбордам), вам нужно перейти в окно Навигации, иконка которого располагается в верхнем тулбаре.
А для того, чтобы перейти к другим чартам или другим объектам внутри DataLens (подключениям, датасетам или дашбордам), вам нужно перейти в окно Навигации, иконка которого располагается в верхнем тулбаре.

Как подобрать подходящий вид визуализации под свою задачу
Немного про разнообразие видов визуализаций
Вообще, графиков и диаграмм придумано так много, что, во-первых, становится все сложнее запоминать их названия, и во-вторых, из них сложно выбирать вид диаграммы, подходящий именно вам для конкретной задачи.
Каждый вид диаграммы выполняет определенную задачу — нужно уметь подбирать наиболее подходящий
В DataLens вам доступно 15 видов чартов. Мы сгруппировали их по целям использования и объединили основные визуализации в наиболее популярные группы сравнения данных:
Каждый вид диаграммы выполняет определенную задачу — нужно уметь подбирать наиболее подходящий
В DataLens вам доступно 15 видов чартов. Мы сгруппировали их по целям использования и объединили основные визуализации в наиболее популярные группы сравнения данных:
- Сравнение категорий
- Соотношение категорий
- Части целого
- Распределение величины
- Изменение во времени
- Изменение на местности

Сравнение категорий
Позволяют продемонстрировать сходства или различия по категориям. В этом виде сравнения основное — это заметить разницу и понять, насколько она велика или мала.
Для сравнения категорий используют столбиковые диаграммы в разных вариациях. А еще столбцы обычно сортируют по убыванию или возрастанию величины — это упрощает сравнение.
Для сравнения категорий используют столбиковые диаграммы в разных вариациях. А еще столбцы обычно сортируют по убыванию или возрастанию величины — это упрощает сравнение.


На этом примере линейчатой диаграммы по оси Y располагаются значения из поля Вид услуги (входящие звонки или исходящие, на городские номера или на мобильные); по оси Х — сумма по стоимости оказанных услуг. В Цвет добавлено поле Измерение тарификации, принимающее два значения — два дискретных цвета на визуализации. Сортировка и подписи к чарту стандартные.
Соотношение
Используют объем или пространство визуализации для отображения возможных взаимосвязей между двумя показателями.
Классический пример — точечная (или пузырьковая) диаграмма, которая показывает наличие или отсутствие зависимости двух переменных.
Классический пример — точечная (или пузырьковая) диаграмма, которая показывает наличие или отсутствие зависимости двух переменных.

Части целого
Показывают, как нечто цельное делится на составные части.
Используются такие диаграммы как круговая, древовидная и накопительные линейчатые диаграммы. Обычно сегменты показателя (его части) также сортируют от большего к меньшему, чтобы визуально упростить считывание данных.
Используются такие диаграммы как круговая, древовидная и накопительные линейчатые диаграммы. Обычно сегменты показателя (его части) также сортируют от большего к меньшему, чтобы визуально упростить считывание данных.


Например, это — круговая диаграмма DataLens по стоимости услуг, разделенная по Направлениям каждого проекта. Каждое направление имеет свой сегмент уникального цвета. Все сегменты по умолчанию отсортированы от большего к меньшему. Плюс, мы добавили подписи к сегментам и поставили настройку подписей в процентах — это можно сделать по клику на решетку # поля в окошке Подписи.
Распределение
величины
величины
Отображают частотность и распределение данных в пределах определенного интервала или по выделенным группам.
Классический пример — гистограмма (или в DataLens — столбчатая диаграмма), в котором каждая полоса на гистограмме представляет частотность значения за определенный интервал — то есть, сколько раз то или иное наблюдение встречается в данных.
Классический пример — гистограмма (или в DataLens — столбчатая диаграмма), в котором каждая полоса на гистограмме представляет частотность значения за определенный интервал — то есть, сколько раз то или иное наблюдение встречается в данных.

Изменение
во
времени
во
времени
Показывают изменение показателя во времени — основную роль тут играет наличие поля с датой по оси Х.

Изменение
на
местности
на
местности
Показывают изменение показателя на местности. Используют карты, на которых откладываются точки координат или географические слои. Сам показатель может выражаться при помощи фоновой заливки элементов карты (областей) или с помощью точек разного размера (чем больше точка, тем больше показатель).

Детализация
В DataLens есть еще три вида чартов, которые не совсем вписываются в описанную выше систему разных видов сравнения данных. Это индикаторы и два вида таблиц. Это очень полезные виды представления данных, хотя это и не визуализация в исходном смысле слова.
Например, таблицы удобно использовать для сравнения конкретных значений, их структура позволяет быстро перемещаться от одной строки к другой, особенно, при наличии сортировки. Таблицы просты в создании и могут пытаться заменить вам все визуальные формы представления данных. Но используйте таблицы только по назначению.
Индикаторы, или KPI – очень и очень востребованный способ показа ключевых цифр, но их следует использовать как один из верхнеуровневых элементов на дашбордах, иначе без контекста они не имеют почти никакого смысла.
Например, таблицы удобно использовать для сравнения конкретных значений, их структура позволяет быстро перемещаться от одной строки к другой, особенно, при наличии сортировки. Таблицы просты в создании и могут пытаться заменить вам все визуальные формы представления данных. Но используйте таблицы только по назначению.
Индикаторы, или KPI – очень и очень востребованный способ показа ключевых цифр, но их следует использовать как один из верхнеуровневых элементов на дашбордах, иначе без контекста они не имеют почти никакого смысла.

Чтобы облегчать задачу выбора подходящей диаграммы были придуманы специальные помощники: чарт-чузеры.
И чтобы вам было интереснее работать с визуализациями, мы рады поделиться своей наработкой по советам использования разных видов диаграмм и визуализаций, которую бережно собрали в сервисе MIRO.
И чтобы вам было интереснее работать с визуализациями, мы рады поделиться своей наработкой по советам использования разных видов диаграмм и визуализаций, которую бережно собрали в сервисе MIRO.

Практика дня
Попробуем разобраться на первом практическом примере




Описание задачи
Вам нужно будет попробовать проделать первые шаги внутри DataLens, которые мы описывали во вчерашнем ДНЕ 00 и СЕГОДНЯ
А именно:
А именно:
- создать подключение к CSV-файлу
- настроить датасет: проставить агрегации и проверить типы полей
- сделать 2-3 простых чарта и посмотреть на настройки этих чартов
В качестве первого учебного примера предлагаем посмотреть на процесс создания простых чартов на примере данных, полученных при выгрузке детализации звонков со своего мобильного оператора.
У вас есть два варианта сделать практику:
Первый вариант. Воспользоваться нашим примером данных "Детализация звонков" – скачать его и загрузить в DataLens.
+ Если вам интересно изучить данные проектов Kickstarter, вы можете скачать их ниже.
У вас есть два варианта сделать практику:
Первый вариант. Воспользоваться нашим примером данных "Детализация звонков" – скачать его и загрузить в DataLens.
+ Если вам интересно изучить данные проектов Kickstarter, вы можете скачать их ниже.
Второй вариант. Сделать собственную выгрузку своих звонков и загрузить ее в DataLens для анализа. Ниже мы приводим ссылки на то, как ее можно получить. Это задание со звездочкой! Предупреждаем, что не на всех тарифах получится сделать детализацию, а некоторые данные придется еще предварительно очистить и подготовить для визуального анализа.

Мегафон
Инструкция тут
Выбрать бесплатную разовую детализацию
Выбрать бесплатную разовую детализацию

МТС

Билайн
Инструкция тут
Максимальный период – 6 месяцев
Максимальный период – 6 месяцев

ТЕЛЕ 2
Инструкция тут
Максимальный период – 6 месяцев
Максимальный период – 6 месяцев
Важно! В DataLens можно загружать только CSV-файлы. Пересохраните файл XLSX в CSV при необходимости вручную или здесь.
Мы посмотрим на практику на примере первого варианта – готового датасета с выгрузкой по Мегафону.
Сама таблица очень простая и состоит всего из 11 столбцов. Пример данных приводим ниже – детализация включает в себя смс, звонки и мобильный трафик. У каждого действия есть дата+время, наименование услуги, направление и набранный номер (если это применимо к типу операции). Также есть числовые показатели – стоимость операции в рублях, объем тарификации (так можно посмотреть сколько мегабайт вы используете в мобильном интернете) и фактический объем услуги.
Сама таблица очень простая и состоит всего из 11 столбцов. Пример данных приводим ниже – детализация включает в себя смс, звонки и мобильный трафик. У каждого действия есть дата+время, наименование услуги, направление и набранный номер (если это применимо к типу операции). Также есть числовые показатели – стоимость операции в рублях, объем тарификации (так можно посмотреть сколько мегабайт вы используете в мобильном интернете) и фактический объем услуги.

После загрузки такой таблицы в DataLens и создания датасета нужно проставить все необходимые агрегации. Мы предлагаем просуммировать все числовые показатели.

Итак...
Попробуйте найти ответы на следующие вопросы:
1. Сколько часов вы говорите по телефону? Сколько в среднем занимает у вас один разговор?
2. С кем вы разговариваете дольше всего и чаще всего? И кто звонит больше – вы или вам?
3. Хватает ли вам текущего пакета минут – иными словами, выгодно ли вам было бы перейти на новый тариф?
- создайте подключение к CSV-файлу
- настройте датасет: проставьте агрегации и проверьте типы полей
- сделайте 2-3 простых чарта, чтобы ответить на вопросы по данным
Попробуйте найти ответы на следующие вопросы:
1. Сколько часов вы говорите по телефону? Сколько в среднем занимает у вас один разговор?
2. С кем вы разговариваете дольше всего и чаще всего? И кто звонит больше – вы или вам?
3. Хватает ли вам текущего пакета минут – иными словами, выгодно ли вам было бы перейти на новый тариф?
Решение от эксперта

Роман Бунин
Руководитель команды визуализации данных Yandex.Go
Когда я только получаю данные, мне всегда хочется «пощупать» и узнать ответы на какие-то довольно простые, но интересные вопросы. Хочется найти какие-то интересные факты. В журналистике такие факты часто можно встретить в виде фактоидов (крупных цифр с интересной информацией): 388 минут проговорил Роман по телефону в декабре, средняя продолжительность звонка составила 73 секунды и т.п. На этом этапе знакомства с данными не нужны красивые и сложные визуализации, часто это просто таблицы или простые графики.
Если бы это были данные с моего телефона, то открыв датасет с детализацией звонков, я задал бы себе простые вопросы:
1) Сколько времени я всего проговорил и сколько денег всего потратил? Мне больше звонили или больше звонил я?
2) Сколько времени в среднем занимает один разговор?
3) Кому я чаще всего звоню? Как часто я звонил маме?
4) С кем я разговариваю в среднем дольше всего?
Ответить на эти вопросы можно с помощью простых графиков и таблиц, вот какие составил я:
Если бы это были данные с моего телефона, то открыв датасет с детализацией звонков, я задал бы себе простые вопросы:
1) Сколько времени я всего проговорил и сколько денег всего потратил? Мне больше звонили или больше звонил я?
2) Сколько времени в среднем занимает один разговор?
3) Кому я чаще всего звоню? Как часто я звонил маме?
4) С кем я разговариваю в среднем дольше всего?
Ответить на эти вопросы можно с помощью простых графиков и таблиц, вот какие составил я:
Оговорюсь, для расчета времени я использовал колонку «протарифиц. объём», что немного завышает время, которое я говорил, так как при этом идёт округление вверх до минуты. Для того чтобы оставить только звонки, я использовал фильтр по виду услуги.
1. Таблички с фильтрами по входящим и исходящим звонкам: за 4 месяца я позвонил 125 раз и принял 82 звонка. Всего проболтал 725 минут (или 12 часов).
Нажимайте на изображения, чтобы их увеличить
Нажимайте на изображения, чтобы их увеличить
 |  |  |
2. Среднее время одного разговора составило 3,52 минуты, а максимальное целых 66 минут.
 |  |
3. Больше десяти раз я общался только с 6 номерами. С мамой говорил всего 8 раз, надо чаще звонить.

4. А вот дольше всего я говорю с партнерами по бизнесу


Вдохновение
... чтобы жить и радоваться данным


Для поиска вдохновения в днях нашего Марафона мы решили написать экспертам в области дизайна, работы с данными и их визуализации и услышать ценное мнение по какой-либо теме. Сегодня говорим про эстетическую составляющую диаграмм: форму, цвет, стиль.

Алексей Новичков
Графический дизайнер, эксперт в области инфографики и независимый консультант, руководитель студии инфографики ТАСС
Ответы на большинство вопросов уже известны
В тот момент, когда ты принимаешь решение о демонстрации результатов своих исследований, появляется множество вопросов, которые имеют отношение к визуализации данных и графическому дизайну. Какой тип диаграммы выбрать? Какие цвета использовать? Как избежать непонимания или неразберихи? Важные вопросы и ответ на них не может быть простым и коротким. Одно можно сказать с уверенностью – ты не первый, кто такие вопросы задаёт, и ответы на большинство из них известны. Многие из них лежат в плоскости здравого смысла или логики.
Форма
Например: не строить столбчатые диаграммы, масштабируя шкалу Y. Согласись, что странно использовать прямоугольные примитивы столбиков, отрезая от них часть. Смысл столбчатых диаграмм в сравнении высоты или длины, а фрагментация делает это сравнение бессмысленным. Другой случай: когда столбиков слишком много. Зачем тебе лес из тонких линий? Ритм их равномерного расположения слишком активный и отвлекает от формы, мешает выявить экстремумы. Замени столбчатую диаграмму на линейный график. Теперь ты можешь спокойно масштабировать ось Y, так как речь идёт не о высоте или длине, а о форме траектории. Ты сможешь сделать акцент на экстремумах, оставив только значимую часть оси Y. Согласись, об этом можно догадаться самому.
Например: не строить столбчатые диаграммы, масштабируя шкалу Y. Согласись, что странно использовать прямоугольные примитивы столбиков, отрезая от них часть. Смысл столбчатых диаграмм в сравнении высоты или длины, а фрагментация делает это сравнение бессмысленным. Другой случай: когда столбиков слишком много. Зачем тебе лес из тонких линий? Ритм их равномерного расположения слишком активный и отвлекает от формы, мешает выявить экстремумы. Замени столбчатую диаграмму на линейный график. Теперь ты можешь спокойно масштабировать ось Y, так как речь идёт не о высоте или длине, а о форме траектории. Ты сможешь сделать акцент на экстремумах, оставив только значимую часть оси Y. Согласись, об этом можно догадаться самому.
Цвет
С цветом всё несколько сложнее. Помнишь, как несколько лет назад люди спорили какого цвета платье на фотографии? Эта оптическая иллюзия происходит от того, что разные люди по разному воспринимают контраст. У нас всего три колбочки, которые воспринимают разные длины волн видимого света, все остальное делает мозг. Не экспериментируй с цветом, если не уверен в результате. Cтарайся применять минимум цветов. Используй красный, синий или зеленый. Окрашивай только акценты или значимые категории данных. Помни про дальтоников – это большой процент населения. Проверяй как график будет читаться, если его распечатают на черно-белом принтере.
С цветом всё несколько сложнее. Помнишь, как несколько лет назад люди спорили какого цвета платье на фотографии? Эта оптическая иллюзия происходит от того, что разные люди по разному воспринимают контраст. У нас всего три колбочки, которые воспринимают разные длины волн видимого света, все остальное делает мозг. Не экспериментируй с цветом, если не уверен в результате. Cтарайся применять минимум цветов. Используй красный, синий или зеленый. Окрашивай только акценты или значимые категории данных. Помни про дальтоников – это большой процент населения. Проверяй как график будет читаться, если его распечатают на черно-белом принтере.
Стиль
Какие выбрать шрифты? Это очень сложный вопрос. Шрифтов очень много и не все они годятся для визуализации данных или для оформления в целом. Одни шрифты редкие и дорогие для использования, другие бесплатные и могли уже примелькаться или вышли из моды. Со шрифтами бывает так же, как и с цветом – одной группе людей нравятся шрифты с засечками, другим рубленные, без засечек. Люди старшего поколения оценят строгий минималистичный стиль с крупными разборчивыми шрифтами, а детям понравятся причудливое оформления, стилизованное под подписи от руки. Возможно у тебя утонченный вкус от рождения и ты сможешь разобраться в графических стилях и модных тенденциях самостоятельно, но знай, что есть профессиональные дизайнеры, которые учатся и доказывают свое мастерство годами. Может имеет смысл использовать уже готовые шаблоны, которые тебе по душе, или прибегать к помощи профессионалов.
Какие выбрать шрифты? Это очень сложный вопрос. Шрифтов очень много и не все они годятся для визуализации данных или для оформления в целом. Одни шрифты редкие и дорогие для использования, другие бесплатные и могли уже примелькаться или вышли из моды. Со шрифтами бывает так же, как и с цветом – одной группе людей нравятся шрифты с засечками, другим рубленные, без засечек. Люди старшего поколения оценят строгий минималистичный стиль с крупными разборчивыми шрифтами, а детям понравятся причудливое оформления, стилизованное под подписи от руки. Возможно у тебя утонченный вкус от рождения и ты сможешь разобраться в графических стилях и модных тенденциях самостоятельно, но знай, что есть профессиональные дизайнеры, которые учатся и доказывают свое мастерство годами. Может имеет смысл использовать уже готовые шаблоны, которые тебе по душе, или прибегать к помощи профессионалов.
Если вы не уверены в своих решениях, то читайте литературу, посещайте митапы или проходите специализированные курсы. Это очень важно – постоянно учиться.
Предлагаем вам также посмотреть наш видео-разговор с Алексеем Новичковым по теме стиля визуализаций и 3D-диаграммам.
Какие 3D визуальные компоненты позволяют управлять информационными потоками организации и поддерживать процессы принятия решений?
Как организациям осознанно применять современные виды визуализаций данных?
Стоит ли использовать пространственные визуализации для решения корпоративных задач анализа данных? Разберемся в деталях.
Как организациям осознанно применять современные виды визуализаций данных?
Стоит ли использовать пространственные визуализации для решения корпоративных задач анализа данных? Разберемся в деталях.
Рома Колеченков позвонит:
Мы создаем DataLens с целью сделать аналитику популярной и доступной для всех категорий пользователей. Марафон для нашей команды — возможность улучшить продукт на основе ваших впечатлений.
Поделитесь своим мнением или идеей, чтобы помочь с развитием
Поделитесь своим мнением или идеей, чтобы помочь с развитием
Образовательный онлайн Марафон DataYoga и Yandex DataLens
thejump@datayoga.ru
2020
thejump@datayoga.ru
2020